4The Role of Informative Priors in Bayesian Inference
4.1 Abstract
Sporting success can be determined by the smallest margins; however, with small sample sizes, detecting these small worthwhile effects is notoriously difficult. Consequently, the call to utilise a Bayesian framework when conducting research to address these issues has increased recently. This study illustrates how Bayesian models can incorporate prior information and how models with more prior information can assist in decision making when margins are small. This study revisits a paper published in this journal investigating the effects of β-alanine on 4-km cycling TT performance through a randomised placebo-controlled trial with 14 trained cyclists. The data set was analysed again in both a frequentist framework and in a Bayesian framework with priors varying in terms of informativeness. In a frequentist framework, there was no significant effect of β-alanine supplementation on 4-km TT performance compared to a placebo. However, a Bayesian model with a very informative prior revealed an estimated 97.8% probability that β-alanine improved performance compared to a placebo, and an estimated 99.0% probability that β-alanine supplementation improved 4-km TT performance compared to baseline. On average, the 4-km TT time decreased by an estimated 6.64 s (-12.20 to -1.19 s), resulting in a small (~2%) but beneficial effect that was more difficult to identify in the previous study using frequentist statistics. While the present study demonstrates why incorporating prior information can increase the power in small-sample research, it also reinforces that β-alanine supplementation may be beneficial for cycling time trials of ~6 min in duration. Using prior predictive distributions can assist researchers in understanding the informativeness of a given prior distribution and should be reported when publishing.
The following chapter is a copy of the submitted manuscript:
Newans, T., Bellinger, P., Drovandi, C., & Minahan, C. The role of informative priors: A new look at the role of β-alanine on 4-km time-trial performance in cyclists. European Journal of Sports Science. Under review.
As co-author of the paper “The role of informative priors: A new look at the role of β-alanine on 4-km time-trial performance in cyclists”, I confirm that Timothy Newans has made the following contributions:
Study concept and design
Data analysis and interpretation
Manuscript preparation
Name: Clare Minahan
Date: 29/03/2023
4.2 Introduction
Sports Scientists are often faced with small sample sizes and/or small effect sizes (Atkinson et al., 2012) and, while these issues are not limited to sports-science research (Bacchetti et al., 2011; Baldwin & Fellingham, 2013; McNeish, 2016; Nomura et al., 2011), they limit the ability to infer changes in the population parameter from sample statistics. Consequently, there has been on-going discussion surrounding the use of probabilistic statements within the sports-science community (Batterham & Hopkins, 2006; Borg et al., 2018; Mengersen et al., 2016; Sainani, 2018; Welsh & Knight, 2015). As such, alternatives to traditional null hypothesis statistical testing have been proposed to provide more insightful inferences in decision making for Sports Scientists (Batterham & Hopkins, 2006). Magnitude-based inferences (MBI), a newly-established method to provide probabilistic inference statements, gained traction quickly, becoming highly cited, and was published in guidelines for authors for some journals (Hopkins et al., 2009). Although MBI received early criticism (Barker & Schofield, 2008), it was still widely adopted. More recently, additional attempts to discredit the concept of MBI were vocalized by Welsh & Knight (2015) who provided a statistical review of the method illustrating unacceptably high levels of Type I errors (Welsh & Knight, 2015). Next, Sainani (2018) weighed into the statistical debate which triggered the sport-science community to critically assess whether MBI should be accepted as a statistical method (Sainani, 2018). Throughout all the rebuttals of MBI (Barker & Schofield, 2008; Borg et al., 2018; Mengersen et al., 2016; Welsh & Knight, 2015), the recurring rhetoric was for Sports Scientists to adopt a ‘fully Bayesian’ approach to provide probabilistic statements when inferring conclusions (Mengersen et al., 2016; Welsh & Knight, 2015).
In 2016, Mengersen and colleagues (Mengersen et al., 2016), provided a worked example and template to perform Bayesian inference in exercise- and sports-science data sets. The paper clearly articulated the need for Bayesian inference for providing probabilistic statements (Mengersen et al., 2016). A growing trend in the use of Bayesian inference in sports science (Santos-Fernandez et al., 2019) has benefited from numerous tutorials being developed to provide readers with the skills in executing Bayesian analyses (Kruschke, 2014; Quintana & Williams, 2018). Nonetheless, there is still a gap in knowledge regarding the appropriateness and benefit of Bayesian inference for Sports Scientists (Mengersen et al., 2016).
Bayesian inference incorporates prior information (‘priors’) to curate the model and can provide estimates with more certainty when compared with frequentist statistical analyses, particularly when informative priors are used (Mengersen et al., 2016). For example, when considering the mean 100-m race time of a sample of elite track sprint runners, a frequentist approach does not impose any constraints on what would be considered realistic sprint times despite our knowledge from extensive historical data, whereas such information can be readily incorporated into a Bayesian approach via a prior distribution. As a result, Bayesian statistics can be more sensitive to small, but real, differences between samples. However, as prior distributions can be used on each parameter within a model (i.e., the intercept, coefficients, variance terms etc.), it is difficult to decipher the interactions between these priors and may unintentionally generate an ‘overly-informative’ prior. Consequently, by sampling parameter values from the prior distribution, and for these parameter values, simulating data from the statistical model, a ‘prior predictive distribution’ can be generated, which can then be compared to the a priori likely values expected in the population to determine if the prior distributions being used are reasonable.
In the present study, we revisited data from an experiment published in 2016 in this journal (Bellinger & Minahan, 2016). In the study by Bellinger & Minahan (2016), fourteen highly-trained cyclists were supplemented with either 6.4 g·day-1 of β-alanine or a placebo for 4 wk. They completed a 1-, 4- and 10-km time trial (TT) as well as a supramaximal cycling bout before and after the supplementation period. Of those performance tasks, the 4-km TT was of most interest given that the duration of the 4-km TT (~6 min) fits within the timeframe most likely to be amenable by β-alanine supplementation (Hobson et al., 2012). However, employing frequentist statistics, β-alanine supplementation was deemed to not significantly alter performance when assuming a 5% significance level (p = 0.060), while a MBI approach demonstrated that there was a 94% likelihood of a beneficial effect of β-alanine supplementation on 4-km TT performance time. Given the shortcomings of the MBI approach (Mengersen et al., 2016) and the discretised significance/non-significance in frequentist statistics (given a p = 0.060 is close to the 5% significance level), we suggest that a Bayesian approach with an informative prior distribution may provide a more precise understanding of the effects of β-alanine supplementation in light of the small sample size.
Consequently, the authors have given permission to re-visit this study and re-analyse this experiment using a Bayesian framework with various prior distributions to illustrate how the different priors result in different interpretations. It is hypothesised that, when using an informative prior, the model could show an improvement (>95% probability) in 4-km TT performance (i.e., reduced time to complete 4 km) with β-alanine.
4.3 Methods
Fourteen trained male cyclists (age = 24.8 ± 6.7 yr, mass = 71.1 ± 7.1 kg, VO2max = 65.4 ± 10.2 mL·kg·min−1) who were currently cycling 250-600 km·wk−1 and competing in either local A-grade criterion or national-road series racing completed the study. For further information regarding the testing protocol, please refer to the previous study (Bellinger & Minahan, 2016).
Show the code:
library(tidyverse)library(brms)library(tidybayes)library(bayestestR)library(patchwork)set.seed(99.94)ba_df <-read_csv("www/data/Study_3_bayesian_beta_alanine.csv") ## Read in databa_df <- ba_df %>%mutate(Diff4k =`Post-4km`-`Pre-4km`) ## Calculate difference in 4km TT
To provide a reproducible example, we made the data from this study publicly available as well as the statistical analyses. While more statistics software programs are providing access to point-and-click Bayesian analyses (e.g., SPSS and Jamovi), the present study chose to conduct all analyses in R for Statistical Computing (R Core Team, 2019) to demonstrate the minimal increase in complexity to progress from frequentist linear models to Bayesian linear models. As the study was a randomised control trial, the β-alanine effect was assessed compared to 0 (i.e., no effect) as well as the placebo group (i.e., placebo effect). Consequently, the β-alanine supplementation group was selected as the reference group (thus the intercept in the model summary can show the effect compared to 0) and the placebo was selected as the alternate treatment (thus the coefficient in the model summary can show the β-alanine effect compared to placebo).
To compare the results of the frequentist and Bayesian frameworks, the frequentist analysis was re-run to confirm the findings of Bellinger & Minahan (2016). This was performed using the lm function in the base R package stats. To provide the greatest accessibility and readability for the Bayesian analyses, the brms package was chosen due to its similarity in structure to the typical lm formula structure. The brms package (Bürkner, 2017) provides an interface to Stan (a very fast programming language written in C++) within R and outputs the results in a similar format to the stats package.
Show the code:
## Frequentist Modelfreq <-lm(Diff4k ~ Treat, data = ba_df) ## Frequentist linear modelsummary(freq) ## Summary of Frequentist modelconfint(freq) ## Confidence Interval of Frequentist model
The model has two regression parameters: the intercept b0 which here corresponds to the mean difference in 4-km times under the treatment, and b1 is the effect of the placebo relative to the treatment, so that b0 + b1 is the mean difference in 4-km times under the placebo. Here we consider imposing different levels of informativeness on the prior predictive distribution of the mean response (difference in 4-km times). The prior predictive distribution of the mean response under the treatment is equivalent to the prior distribution of b0 for this model.
Firstly, the flat priors for b0 and b1 were considered; however, as the brms package does not allow for flat priors, a normal prior was assigned to b0 and a normal prior assigned to b1, both with a mean of 0 and a SD of 10000 to act as an uninformative prior. For this prior configuration, 48.6% of the prior predictive values of the mean response were theoretically impossible under the treatment, as a 4-km TT lasting on average 360 s cannot have, on average, an improvement of more than 360 s and, as a result, no model was built using this prior.
Show the code:
## Uninformative Prior Modelpnorm(-360,0,10000) # Probability of -360 s or larger decrease in 4km TT given a mean = 0 and SD = 10,000
Consequently, the first Bayesian model (Model 1) used was built with a normal prior distribution (mean = 0, SD = 72) for the mean response of both b0 and b1. Here, 1 SD (i.e., 72 s) represented a 20% improvement or decrement in performance under the treatment. The β-alanine treatment was set as the default baseline in the model so that the intercept represented the β-alanine treatment effect (i.e., is the β-alanine treatment effect different from zero), while the b coefficient represented the placebo level (i.e., is the β-alanine treatment effect different from a placebo). The prior for the normal response standard deviation, sigma, was kept controlled across all models to allow for consistency, in which the default-selected brms prior was used, in this case a half t-distribution with a mean of 0 and SD of 6.3 with 3 degrees of freedom.
Show the code:
## Model 1 - Vague Prior Modelmean_v <-0## Set vague prior mean to 0sd_v <-72## Set vague prior mean to 72pnorm(-100,mean_v,sd_v) +1-pnorm(100,mean_v,sd_v) ## Calculate probability the treatment effect is greater than 100 svague <-brm(Diff4k ~ Treat, iter =10000, chains =8, data = ba_df, seed =99.94,prior =c(set_prior(paste0("normal(",mean_v,",",sd_v,")"), class ="Intercept"),set_prior(paste0("normal(",mean_v,",",sd_v,")"), class ="b"))) ## Run Bayesian linear model for Treatment effect on 4km TT with a vague prior
The second Bayesian model (Model 2) used was built with a normal prior distribution (mean = 0, SD = 18) for both b0 and b1, with 1 SD (i.e., 18 s) representing a 5% improvement or decrement in performance under the treatment.
Show the code:
## Model 2 - Informative Prior Modelmean_i <-0## Set informative prior mean to 0sd_i <-18## Set informative prior SD to 18pnorm(-50,mean_i,sd_i) +1-pnorm(50,mean_i,sd_i) ## Calculate probability the treatment effect is greater than 50 s1-pnorm(-10,mean_i,sd_i) - (1-pnorm(10,mean_i,sd_i)) ## Calculate probability the treatment effect is less than 10 sinformative <-brm(Diff4k ~ Treat, data = ba_df, iter =10000, chains =8, seed =99.94,prior =c(set_prior(paste0("normal(",mean_i,",",sd_i,")"), class ="Intercept"),set_prior(paste0("normal(",mean_i,",",sd_i,")"), class ="b"))) ## Run Bayesian linear model for Treatment effect on 4km TT with an informative prior
The final Bayesian model (Model 3) was built with a normal prior distribution (mean = -10.26, SD = 18) for b0, representing a 2.85% improvement in performance, the estimated effect of β-alanine supplementation as outlined in the previously-completed meta-analysis (Hobson et al., 2012). A normal prior distribution (mean = 10.26, SD = 18) was chosen for b1, with 1 SD (i.e., 18 s) to again represent a 2.85% improvement in performance because of β-alanine supplementation.
Show the code:
## Model 3 - Very Informative Prior Modelmean_vi <--10.28## Set very informative prior mean to -10.28sd_vi <-18## Set very informative prior SD to 181-pnorm(-37.76,mean_vi,sd_vi) - (1-pnorm(1.33,mean_vi,sd_vi)) ## Calculate probability the treatment effect is between the confidence interval seen in meta-analysisveryinformative <-brm(Diff4k ~ Treat, data = ba_df, iter =10000, chains =8, seed =99.94,prior =c(set_prior(paste0("normal(",mean_vi,",",sd_vi,")"), class ="Intercept"),set_prior(paste0("normal(",-mean_vi,",",sd_vi,")"), class ="b"))) ## Run Bayesian linear model for Treatment effect on 4km TT with a very informative prior
4.4 Results
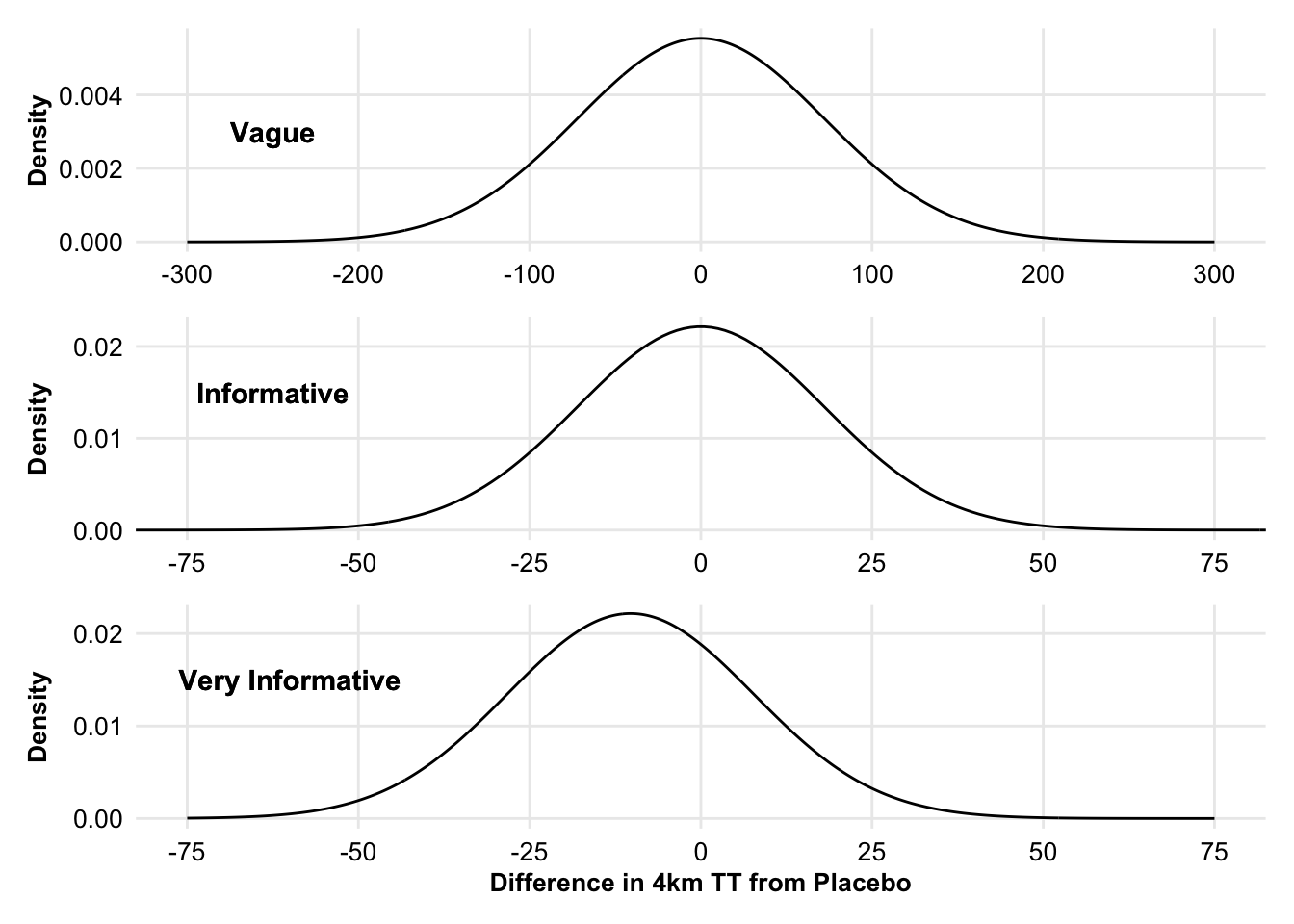
To illustrate the differences in the priors, the density curves of the prior predictive distribution of the mean response under the treatment were constructed, which for this model, corresponds to the prior distribution for b0. The varying prior predictive distributions for the mean effect of β-alanine are displayed in Figure 4.1. As expected, the first two distributions are centred around the mean of 0 with differing variances, with the third distribution displaying the same variance as the third distribution, just left-shifted to a mean of -10.26, as specified in the model. The density curves in Figure 4.1 show the sample space that each Bayesian model was “constrained to”, illustrating the more-informative priors (e.g., Model 2 and Model 3).
Show the code:
vpriorplot <-ggplot(data.frame(x =c(-300, 300)), aes(x)) +stat_function(fun = dnorm, n =600, args =list(mean = mean_v, sd = sd_v)) +geom_text(aes(x =-250, y =0.003), label ="Vague", fontface ="bold")+scale_x_continuous(breaks =c(seq(-300,300, by =100)))+theme_minimal()+labs(y ="Density")+theme(axis.title.x =element_blank(),panel.grid.minor =element_blank(),axis.title.y =element_text(size =10, color ="black", face ="bold"),axis.text =element_text(size =10, color ="black")) ## Visualise the prior predictive distribution given a vague priorinfpriorplot <-ggplot(data.frame(x =c(-300, 300)), aes(x)) +stat_function(fun = dnorm, n =600, args =list(mean = mean_i, sd = sd_i)) +geom_text(aes(x =-62.5, y =0.015), label ="Informative", fontface ="bold")+theme_minimal()+labs(y ="Density")+scale_x_continuous(breaks =c(seq(-75,75, by =25)))+scale_y_continuous(breaks =c(seq(0,0.02, by =0.01)))+coord_cartesian(xlim =c(-75,75))+theme(axis.title.x =element_blank(),panel.grid.minor =element_blank(),axis.title.y =element_text(size =10, color ="black", face ="bold"),axis.text =element_text(size =10, color ="black")) ## Visualise the prior predictive distribution given an informative priorvinfpriorplot <-ggplot(data.frame(x =c(-75, 75)), aes(x)) +stat_function(fun = dnorm, n =600, args =list(mean = mean_vi, sd = sd_vi)) +geom_text(aes(x =-60, y =0.015), label ="Very Informative", fontface ="bold")+theme_minimal()+labs(x ="Difference in 4km TT from Placebo", y ="Density")+scale_x_continuous(breaks =c(seq(-75,75, by =25)))+scale_y_continuous(breaks =c(seq(0,0.03, by =0.01)))+coord_cartesian(xlim =c(-75,75),ylim =c(0,0.022))+theme(panel.grid.minor =element_blank(),axis.title =element_text(size =10, color ="black", face ="bold"),axis.text =element_text(size =10, color ="black")) ## Visualise the prior predictive distribution given a very informative priorvpriorplot / infpriorplot / vinfpriorplot
Figure 4.1: Prior predictive distributions of the mean pre-post change in 4-km time trial (TT) difference under the β-alanine supplementation based on three prior distributions that differ in terms of level of informativeness.
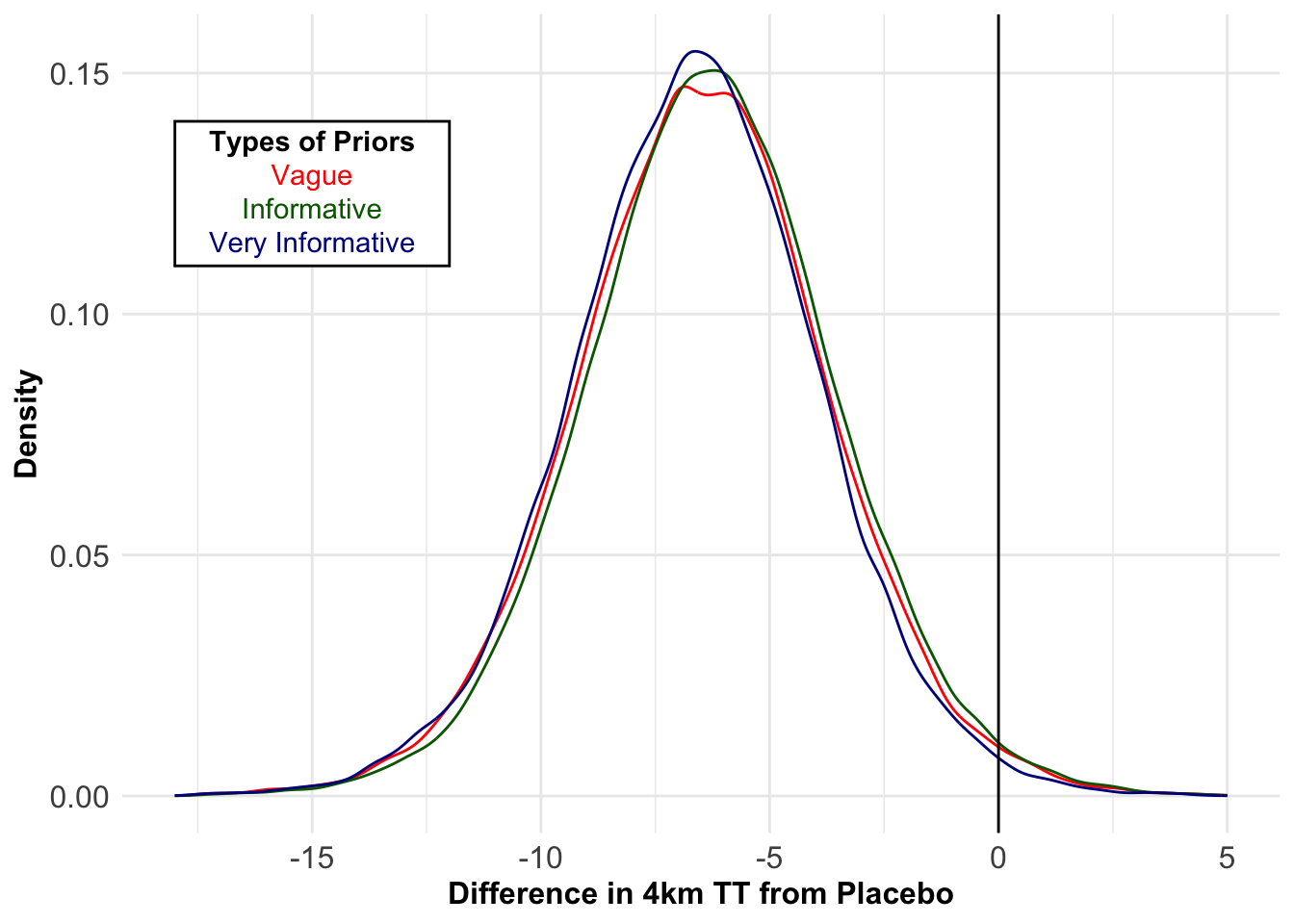
The results from the frequentist model and the three Bayesian models are displayed in Table 4.1. In the frequentist model, at the 5% significance level, the intercept (i.e., β-alanine effect) was significantly different from zero (t(12) = -2.45, p = 0.031), although the coefficient (i.e., β-alanine compared to a placebo) was not significant (t(12) = 2.08, p = 0.060), confirming previous findings by the authors (Bellinger & Minahan, 2016). Model 3, the Bayesian model with the very informative prior, displayed a 99.0% probability that β-alanine decreases the mean 4-km TT time, and that this decrease was, on average, by 6.64 s.
Table 4.1: Comparison of frequentist and various Bayesian models with different priors.
Model
Intercept (i.e., β-alanine effect)
Coefficient (i.e., β-alanine vs Placebo)
Frequentist
-6.47 (-12.23 to -0.72)
7.76 (-0.38 to 15.91)
Bayesian - Vague
-6.46 (-12.09 to -0.84)
7.71 (-0.22 to 15.69)
Bayesian - Informative
-6.25 (-11.73 to -0.72)
7.39 (-0.44 to 14.99)
Bayesian - Very Informative
-6.64 (-12.20 to -1.19)
7.88 (0.30 to 15.64)
N.B. Frequentist values are presented as mean (95% confidence interval), while Bayesian values are presented as mean (95% credible interval).
When comparing β-alanine with a placebo, there is a 97.8% probability that β-alanine improves mean 4-km TT performance compared to a placebo. The posterior distributions of the pre-post difference in mean 4-km TT performance from each of the three Bayesian models are displayed in Figure 4.2.
Show the code:
## Draws from posterior distributionvagueplot <- vague %>%spread_draws(b_Intercept,b_TreatPL) %>%mutate(PL = b_TreatPL-b_Intercept) ## Calculate placebo effects for Model 1informativeplot <- informative %>%spread_draws(b_Intercept,b_TreatPL) %>%mutate(PL = b_TreatPL-b_Intercept) ## Calculate placebo effects for Model 2veryinformativeplot <- veryinformative %>%spread_draws(b_Intercept,b_TreatPL) %>%mutate(PL = b_TreatPL-b_Intercept) ## Calculate placebo effects for Model 3## Posterior Predictive Distribution Figureggplot()+geom_density(data = vagueplot, aes(x = b_Intercept), color ="red")+geom_density(data = informativeplot, aes(x = b_Intercept), color ="darkgreen")+geom_density(data = veryinformativeplot, aes(x = b_Intercept), color ="darkblue")+geom_rect(aes(xmin =-18,xmax =-12,ymin =0.11, ymax =0.14), fill ="white",color ="black")+geom_text(aes(x =-15,y =0.136), label ="Types of Priors", fontface ="bold",color ="black")+geom_text(aes(x =-15,y =0.129), label ="Vague", color ="red")+geom_text(aes(x =-15,y =0.122), label ="Informative", color ="darkgreen")+geom_text(aes(x =-15,y =0.115), label ="Very Informative", color ="darkblue")+geom_vline(xintercept =0)+labs(x ="Difference in 4km TT from Placebo",y ="Density")+theme_minimal()+scale_x_continuous(limits =c(-18,5))+theme(legend.position ="bottom",axis.title =element_text(size =12,face ="bold"),axis.text =element_text(size =12),panel.grid.minor.y =element_blank())
Figure 4.2: Posterior distributions of the mean pre-post change in 4-km time trial (TT) difference between β-alanine supplementation and placebo from three Bayesian models with differing priors.
4.5 Discussion
This study updates the literature on the effect of β-alanine on a 4-km cycling TT performance and outlines how informative priors can provide more meaningful statistical analyses in a Bayesian framework compared to a frequentist framework. The present study showed that, with the most-informative prior, there was an estimated 99.0% probability that β-alanine improves the 4-km TT performance and an estimated 97.8% probability that β-alanine improves performance more than a placebo. On average, 4-km TT performance decreased by an estimated 6.64 s, confirming similar findings by the authors in the previously published paper (Bellinger & Minahan, 2016). Consequently, it is reinforced that β-alanine supplementation is likely to provide an ergogenic effect to maximal effort time trials with a duration of ~6 min. While the exact mechanisms underpinning how increased carnosine contributes to improved exercise performance requires further clarification, the ergogenic effect is likely due to enhanced muscle contractile properties (Dutka et al., 2012; Everaert et al., 2013), and/or an increase in intracellular buffering capacity (Baguet et al., 2010).
A main feature of the present study was the use of prior predictive distributions to ensure the priors encapsulated the possible sample space for the mean of the response variable (in this case, change in 4-km TT performance). While this study sought to keep the methodology simple by only generating prior predictive distributions for the mean of the response variable, the prior predictive distribution can often be impacted by the interaction between the different priors (e.g., intercept, levels in conditions, variances, covariances etc.). Therefore, sampling from the prior distribution is essential to ensure the prior predictive distribution both captures all the practically possible values of the mean, as well as minimises practically impossible values. As humans struggle to conceptualise probabilities (Gillies, 2000), it is helpful to visualise this prior predictive distribution to ensure the Bayesian model does not contain too-informative priors that unintentionally bias the model. In the first instance of using Bayesian analyses, it is natural to start with uninformative priors in a bid to minimise the bias of running an analysis and align as close to a frequentist framework as possible. However, by providing such wide priors as seen in the uninformative prior, it unintentionally introduces a bias towards unrealistic values. Consequently, providing priors based on previously published studies in similar populations or subject matter expert knowledge is required (Zondervan-Zwijnenburg et al., 2017).
After visualising the prior predictive distributions of the mean for the vague and informative models (i.e., Models 1 & 2), it is evident that more-constrained prior distributions are required due to the elite nature of the athletes involved. That is, in the vague prior predictive distribution, 16.5% of the distribution still predicted that β-alanine would, on average, affect the 4-km TT by more than 100 s. When narrowing the prior for the informative model, only 0.5% of the distribution predicted that β-alanine would, on average, affect the 4-km TT by more than 50 s. However, being a normal distribution, it also disadvantaged the model. As it was centred around 0, 42.1% of the prior distribution predicted that β-alanine would not affect the 4-km TT by more than 10 s (i.e., that is the mean effect is between -10 and 10 s). This is now deemed “too informative” as a prior meta-analysis had shown that the median effect of β-alanine was 2.85% which would be approximately 10 s. This was evident in the resultant models, with the coefficient reducing from the vague (7.75 s) to the informative model (7.28 s). Consequently, by translating the informative prior to a mean of -10.26 s in line with the previous meta-analysis, 67.7% of the prior predictive distribution contained values within a 0.3% decrement in performance (1.33 s) and 10.49% improvement (37.76 s) in performance, the two limits of the confidence interval from the meta-analysis.
When comparing the results to the frequentist model previously used, the informative priors were able to not only show that β-alanine supplementation improved performance, but the interpretation of the results is also more translatable than in a frequentist framework. The frequentist interpretation of p = 0.06 would be that, if the experiment were to be replicated infinitely many times, there would be a 6% chance that the true population mean difference between β-alanine and a placebo was 0, and 95% of the time, the interval (-0.38 to 15.91 s) would include the true population parameter. However, in a Bayesian framework, the probability that β-alanine is better than a placebo can be estimated (i.e., 97.8%) and that there is a 95% probability that the true population mean is between 0.30 to 15.64 s can also be calculated.
While this study is only one example of how prior distributions can impact on the statistical model in a Bayesian context, it shows researchers and Sports Scientists the process of selecting informative priors by generating prior predictive distributions and critiquing the suitability of those priors given the knowledge of the data being collected. Narrowing the standard deviation of the prior distribution can adjust the prior predictive distribution to encapsulate the valid range of values seen in the population. Similarly, by shifting the mean according to prior information (in this case, a meta-analysis), smaller effects can be identified by utilising that prior information. One potential risk of informative priors is that, if not specified appropriately, it may conflict with the information provided in the data (Evans & Moshonov, 2006). This potential prior-data conflict can be examined by comparing the prior and posterior distributions and verifying that the posterior distribution does not lie in the tail of the prior. Therefore, it is recommended to visualise both the prior and posterior distributions. There is also scope for Bayesian models to address similar issues where coaches may only prescribe training for one athlete. Given athletes are being observed on a daily basis (Thornton et al., 2019), utilising previous daily measurements may allow the for the assessment of individual changes in response to a particular intervention.
The present study has demonstrated that Sports Scientists could adopt Bayesian models in research to apply appropriately sensitive statistical methodologies when measuring small effect sizes and small samples. The use of prior predictive distributions allows the researcher to visualise the constraints each prior has on the model to ensure it reflects information that may be available from domain experts or previous studies. It should also be noted, that just because a more-informative prior is used, a significant effect may not be present in the true population and therefore assessment that the informative priors are sound is required. Consequently, future studies being published using a Bayesian framework should outline the priors used for model components as well as the prior predictive distribution generated from the prior distributions. In doing so, readers can understand the sample space prior to the model and provides greater context for the posterior distribution to ensure transparency in the results being produced.
Atkinson, G., Batterham, A., & Hopkins, W. (2012). Sports performance research under the spotlight. International Journal of Sports Medicine, 33(12), 949. https://doi.org/10.1055/s-0032-1327755
Bacchetti, P., Deeks, S., & McCune, J. (2011). Breaking free of sample size dogma to perform innovative translational research. Science Translational Medicine, 3(87), 87ps24. https://doi.org/10.1126/scitranslmed.3001628
Baguet, A., Koppo, K., Pottier, A., & Derave, W. (2010). Β-alanine supplementation reduces acidosis but not oxygen uptake response during high-intensity cycling exercise. European Journal of Applied Physiology, 108(3), 495–503. https://doi.org/10.1007/s00421-009-1225-0
Baldwin, S., & Fellingham, G. (2013). Bayesian methods for the analysis of small sample multilevel data with a complex variance structure. Psychological Methods, 18(2), 151. https://doi.org/10.1037/a0030642
Barker, R., & Schofield, M. (2008). Inference about magnitudes of effects. International Journal of Sports Physiology and Performance, 3(4), 547–557. https://doi.org/10.1123/ijspp.3.4.547
Batterham, A., & Hopkins, W. (2006). Making meaningful inferences about magnitudes. International Journal of Sports Physiology and Performance, 1(1), 50–57. https://doi.org/10.1123/ijspp.1.1.50
Bellinger, P., & Minahan, C. (2016). The effect of β-alanine supplementation on cycling time trials of different length. European Journal of Sport Science, 16(7), 829–836. https://doi.org/10.1080/17461391.2015.1120782
Borg, D., Minett, G., Stewart, I., & Drovandi, C. (2018). Bayesian methods might solve the problems with magnitude-based inference. A letter in response to Dr. Sainani. Medicine and Science in Sports and Exercise, 50(12), 2609–2610. https://doi.org/10.1249/mss.0000000000001736
Bürkner, P.-C. (2017). Brms: An r package for bayesian multilevel models using stan. Journal of Statistical Software, 80(1), 1–28. https://doi.org/10.18637/jss.v080.i01
Dutka, T., Lamboley, C., McKenna, M., Murphy, R., & Lamb, G. (2012). Effects of carnosine on contractile apparatus Ca2+ sensitivity and sarcoplasmic reticulum Ca2+ release in human skeletal muscle fibers. Journal of Applied Physiology, 112(5), 728–736. https://doi.org/10.1152/japplphysiol.01331.2011
Evans, M., & Moshonov, H. (2006). Checking for prior-data conflict. Bayesian Analysis, 1(4), 893–914. https://doi.org/10.1214/06-BA129
Everaert, I., Stegen, S., Vanheel, B., Taes, Y., & Derave, W. (2013). Effect of beta-alanine and carnosine supplementation on muscle contractility in mice. Medicine and Science in Sports and Exercise, 45(1), 43–51. https://doi.org/10.1249/mss.0b013e31826cdb68
Hobson, R., Saunders, B., Ball, G., Harris, R., & Sale, C. (2012). Effects of β-alanine supplementation on exercise performance: A meta-analysis. Amino Acids, 43(1), 25–37. https://doi.org/10.1007/s00726-011-1200-z
Hopkins, W., Marshall, S., Batterham, A., & Hanin, J. (2009). Progressive statistics for studies in sports medicine and exercise science. Medicine & Science in Sports & Exercise, 41(1), 3–12. https://doi.org/10.1249/MSS.0b013e31818cb278
McNeish, D. (2016). On using bayesian methods to address small sample problems. Structural Equation Modeling: A Multidisciplinary Journal, 23(5), 750–773. https://doi.org/10.1080/10705511.2016.1186549
Mengersen, K., Drovandi, C., Robert, C., Pyne, D., & Gore, C. (2016). Bayesian estimation of small effects in exercise and sports science. PLoS One, 11(4), e0147311. https://doi.org/10.1371/journal.pone.0147311
Quintana, D., & Williams, D. (2018). Bayesian alternatives for common null-hypothesis significance tests in psychiatry: A non-technical guide using JASP. BMC Psychiatry, 18(1), 178.
R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
Santos-Fernandez, E., Wu, P., & Mengersen, K. (2019). Bayesian statistics meets sports: A comprehensive review. Journal of Quantitative Analysis in Sports, 15(4), 289–312. https://doi.org/10.1186/s12888-018-1761-4
Thornton, H., Delaney, J., Duthie, G., & Dascombe, B. (2019). Developing athlete monitoring systems in team sports: Data analysis and visualization. International Journal of Sports Physiology and Performance, 14(6), 698–705. https://doi.org/10.1123/ijspp.2018-0169
Welsh, A., & Knight, E. (2015). “Magnitude-based inference”: A statistical review. Medicine and Science in Sports and Exercise, 47(4), 874–884. https://doi.org/10.1249/MSS.0000000000000451
Zondervan-Zwijnenburg, M., Peeters, M., Depaoli, S., & Van de Schoot, R. (2017). Where do priors come from? Applying guidelines to construct informative priors in small sample research. Research in Human Development, 14(4), 305–320. https://doi.org/10.1080/15427609.2017.1370966