Elite team sports are challenged by the need to possess multiple, often conflicting, athlete characteristics (e.g., sprint ability and endurance) to maximise match running performance and tactics. Univariate analysis of athlete characteristics is commonplace in sports science whereby speed is typically evaluated independently of endurance. While this methodology readily identifies athletes excelling in either speed or endurance, it fails to highlight athletes who possess ‘the best compromise’ in speed and endurance. This study presents an innovative approach to evaluating running intensity during short (10 s; anaerobic power/speed) and long (20 min; aerobic power/endurance) periods during football matches by using the Pareto frontier to visualize athlete characteristics simultaneously. Importantly, this study was the first to quantify the uncertainty around the Pareto frontier, using samples drawn from the Bayesian posterior distribution of both rolling averages to calculate the probability an athlete sits on the true population Pareto frontier. The 10-s and 20-min rolling averages were calculated (325.1 and 104.7 m·min-1, respectively) for 18 elite female footballers across three seasons using a Bayesian mixed model. No linear relationship between the two periods was identified when considering the entire sample (n = 18, r = 0.03). However, a moderate negative linear relationship was observed when only considering athletes that were on the first three (i.e., outer most) Pareto frontiers (n = 12, r = -0.49). The Pareto frontier provides coaches with a holistic view of their athletes’ speed and endurance capabilities and enables a more informed decision when identifying the athletes with the optimal balance of these polarizing attributes.
The following chapter is a copy of a manuscript in preparation:
Newans, T., Bellinger, P., Drovandi, C., Griffin, J. & Minahan, C. Bayesian approximation of the trade-off relationship between running intensity measured during short and long periods using Pareto frontiers. In preparation.
As co-author of the paper “Bayesian approximation of the trade-off relationship between running intensity measured during short and long periods using Pareto frontiers”, I confirm that Timothy Newans has made the following contributions:
Study concept and design
Data collection
Data analysis and interpretation
Manuscript preparation
Name: Clare Minahan
Date: 29/03/2023
6.2 Introduction
Many team-based ball sports (e.g., soccer, rugby, Australian football) comprise intermittent high-intensity locomotion (i.e., high-speed running and sprinting) interspersed among continuous low-intensity locomotion (Coutts et al., 2010; Deutsch et al., 2007; Newans et al., 2021; Stølen et al., 2005). Defined ‘speed zones’ (km/h) have been previously used to examine the total number of efforts or the total distance covered by an athlete at various locomotive intensities across a match (Cummins et al., 2013; Dalton-Barron et al., 2020; Quinn et al., 2020). However, by simply aggregating the number of efforts or total distance performed within each speed zone, Sports Scientists were unable to identify the most intense period of a match, making it difficult to prescribe match-specific training interventions (Mohr et al., 2003). In recent years, new analysis techniques, such as the rolling-average method (Delaney et al., 2015; Varley et al., 2012), have been used to quantify the locomotive intensity of athletes more precisely during match play expressing intensity as distance covered per minute (i.e., m/min (Cunningham et al., 2018)). Indeed, rolling-average analyses can quantify athletes’ locomotive intensity over both short (e.g., < 1 min) and long (e.g., > 10 min) intervals which provide sophisticated data about each athlete’s unique running ability which in turn can assist sports scientists and conditioning coaches in prescribing individualized match-specific training interventions (Delaney et al., 2015; Fereday et al., 2020). While new metrics have been devised to calculate the metabolic costs of both these tasks (Brown et al., 2016; Buchheit et al., 2015), little consideration has been given to which task is the larger contributor toward these new metrics for athletes with differing movement patterns. Despite the documented usefulness of independently quantifying duration-specific running intensities in athletes during match play (Delaney et al., 2015; Fereday et al., 2020), there may be a trade-off or compromise between the running performance during short and long periods that remains unexplored.
It is true that athletes who possess a high maximal anaerobic power (i.e., speed) are unlikely to also possess a high aerobic power (i.e., endurance) (McKay et al., 2021) when compared with other elite athletes. Therefore, it is reasonable to assume that elite team-sport athletes who can maintain a relatively high intensity during short locomotive efforts (e.g., <1 min) will be unable to maintain a relatively high intensity over long locomotive efforts (e.g., >10 min), and vice versa. While univariate statistics can easily identify athletes at both extremes (i.e., those with high speed or high endurance profiles), it is more difficult to ascertain athletes who are uniquely proficient at both, possessing the best compromise between speed and endurance. No previous statistical approach has been used in sports science to meaningfully identify the ‘extreme all-rounder’ of short- and long-duration running performance in elite team-sport athletes.
Presented with a similar quandary in T20 cricket, whereby the number of runs scored per dismissal (i.e., batting average) and the rate at which the athlete scores runs relative to the number of balls faced (i.e., batting strike rate) are negatively correlated (Newans, Bellinger, & Minahan, 2022). We utilised Pareto frontiers to: i. Athletes with the highest batting average, ii. Athletes with the highest strike rate, and iii. Athletes possessing the best compromise between batting average and strike rate (Newans, Bellinger, & Minahan, 2022). Indeed, Pareto frontiers are a relatively new statistical approach to analyzing sports science data that may assist in the identification of athletes who are not necessarily specialists in one metric but possess the best compromise on two or more opposing abilities.
However, when dealing with longitudinal data sets such as locomotive movement patterns, the uncertainty around an athlete’s movement patterns when each athlete has multiple observations needs to be accounted for (Newans, Bellinger, Drovandi, et al., 2022). In this instance, mixed models are required to account for this longitudinal data set (Newans, Bellinger, Drovandi, et al., 2022) and the regression framework also allows the model to adjust for other variables in the data. Furthermore, when executing the mixed model in a Bayesian framework, the probability of an athlete being a member of the Pareto frontier for each athlete by resampling from the posterior distribution of the athletes’ effects can be estimated. While Bayesian Pareto frontiers have previously been explored in portfolio construction in economics (Bauder et al., 2021), we do not believe that Bayesian Pareto frontiers have been constructed while accounting for the uncertainty due to the repeated-measures nature of the data.
Therefore, in the present study, we analyse running intensities in short- (i.e., 10 s) and long- (i.e., 20 min) efforts during match play to identify athletes at both extremes as well as athletes possessing the best compromise between running intensity over short and long durations. To accommodate multiple observations from each athlete, this study proposes to use a mixed model within a Bayesian framework to quantify the uncertainty around each athlete’s locomotion. Specifically, Pareto frontiers generated from the posterior distribution of each running intensity were established to highlight the trade-off nature between the two intensities, having accounted for uncertainty through a Bayesian mixed model.
6.3 Methods
The locomotive activities of eighteen female football athletes competing in the Australian women’s domestic football league were analysed. All athletes were from the same team and thirty-three matches across three seasons (2017-2019) were analysed. Only data where an athlete completed the full match (i.e., 90-min) was included in the study. A minimum of three matches was required for each athlete to ensure that the means were not too heavily impacted by individual match demands. Goalkeepers were excluded from the data set due to their vastly different locomotion patterns. Collectively, there were 154 unique match files in the data set. This study was approved by the Griffith University (GU) Human Ethics Committee and Football Federation Australia (GU Ref: 2019/359).
Locomotion patterns were measured using 10 Hz VX GPS units (Visuallex Sport International, Wellington, New Zealand) with the 10 Hz velocity data exported for each match file. The units in the present study have been reported to have acceptable accuracy and both between- and within-manufacturer reliability for quantifying locomotion patterns during team sport (Delaney et al., 2019; Varley et al., 2012).
To summarise the locomotion patterns of each athlete, a customised R-script was used to calculate the rolling averages. To define the high-intensity locomotion, a 10-second rolling average was iterated over each match file to identify the peak short-duration running intensity period, while a 20-minute rolling average was used to define the peak long-duration running intensity period. Given the inherent variability within athletes and given the imbalanced nature of the data set (range: 1-20 matches per athlete), mixed models were used to address this issue (Newans, Bellinger, Drovandi, et al., 2022).
Show the code:
library(tidyverse)library(brms)library(tidybayes)library(rPref)bayespareto <-read_csv("www/data/Study_5_bayesian_pareto_mm.csv") # Read in databayespareto <- bayespareto %>%mutate(R10s = R10s*6,R20m = R20m/20) # Convert distances to intensity (metres per minute)
The Pareto frontier that was to be generated was to identify the athletes in which no other athlete is higher in both the 10-second (short duration) and 20-minute (long duration) rolling averages. For the Pareto frontier to be generated, the means in both the running intensities for each athlete were calculated. Consequently, a mixed model within a Bayesian framework was employed to estimate the posterior distribution for each athlete, having accounted for the uncertainty of each athlete’s mean based on the number of observations. As the rolling 10-second and 20-minute periods are inherently related, a bivariate model was implemented and defined by the following equation:
\(S_{apm}\) is the response variable for the 10-second rolling average for the \(a\)th athlete, \(p\)th position, and \(m\)th match
\(L_{apm}\) is the response variable for the 20-minute rolling average for the \(a\)th athlete, \(p\)th position, and \(m\)th match
\(\beta_0^S\) is the intercept related to the 10-second rolling average response variable
\(\beta_0^L\) is the intercept related to the 20-minute rolling average response variable
\(\beta_a^S\) is the athlete fixed effect related to the 10-second rolling average response variable
\(\beta_a^L\) is the athlete fixed effect related to the 20-minute rolling average response variable
\(\beta_p^S\) is the position random effect related to the 10-second rolling average response variable
\(\beta_p^L\) is the position random effect related to the 20-minute rolling average response variable
\(\beta_m^S\) is the match random effect related to the 10-second rolling average response variable
\(\beta_m^L\) is the match random effect related to the 20-minute rolling average response variable
\(\epsilon_{apm}^S\) is the residual related to the 10-second rolling average response variable
\(\epsilon_{apm}^L\) is the residual related to the 20-minute rolling average response variable
The random effects are assumed to be normally distributed, \(\beta_p^S\ \sim N(0,\phi_p^S)\), \(\beta_p^L\ \sim N(0,\phi_p^L)\), \(\beta_m^S\ \sim N(0,\phi_m^S)\), \(\beta_m^L\ \sim N(0,\phi_m^L)\) where \(\phi_p^S\), \(\phi_p^L\), \(\phi_m^S\), \(\phi_m^L\) are variances to be estimated. The residuals are assumed to have a bivariate normal distribution: \[
\begin{bmatrix} \epsilon_{apm}^S\\\epsilon_{apm}^L\end{bmatrix} \sim N(\begin{bmatrix} 0\\0\end{bmatrix},\Sigma)
\] where \(\Sigma\) is a 2x2 covariance matrix which is estimated.
The mixed model allowed for the visualisation of the estimated conditional athlete effects for low and high intensity periods and utilised Pareto frontiers to identify the “extreme” athletes. As some athletes played in multiple positions across the three years, position was included as a random effect alongside the match ID to account for match-to-match variability in the team. A normal prior with a mean of 0 and SD of 30 was set for the regression coefficients related to both the rolling 10-second and the rolling 20-minute averages, which was derived from the standard deviations of the ‘worst-case scenarios’ identified in prior studies utilising rolling averages in football (Doncaster et al., 2020; Fereday et al., 2020). ‘Worst-case scenario’ analyses have recently come under scrutiny (Novak et al., 2021) to use as a prescriber for training programs as they do not consider the psycho-physiological responses to the given stimulus. However, there is still merit in utilising these analyses to better understand the locomotive requirements of game play comparative to whole-match or half totals or averages (Weaving et al., 2022).
Show the code:
univariate_model_R10s <-brm(R10s ~ (1|Player) + (1|Position) + (1|SeasonGame), iter =4000, chains =8, data = bayespareto,seed =99.94) # Build univariate model for rolling 10-second averageunivariate_model_R20m <-brm(R20m ~ (1|Player) + (1|Position) + (1|SeasonGame), iter =4000, chains =8, data = bayespareto,seed =99.94) # Build univariate model for rolling 20-minute averagemultivariate_model <-brm(mvbind(R10s,R20m) ~ Player + (1|Position) + (1|SeasonGame), iter =8000, chains =8, data = bayespareto,seed =99.94,prior =c(set_prior("normal(0,30)", class ="b",resp ="R10s"),set_prior("normal(0,30)", class ="b",resp ="R20m"))) # Build multivariate model for rolling 10-second and 20-minute average
While the Pareto frontier for the sample could be established from the conditional means arising from the mixed model, the uncertainty around each athlete’s mean because of match-to-match variability meant that other athletes could be on the ‘true’ population Pareto frontier as well. To solve this, the multivariate mixed model was implemented in a Bayesian framework, to allow samples to be drawn from the posterior predictive distribution of both the 10-second and 20-minute rolling averages, in which the Pareto frontier could be generated for each sample. To quantify the uncertainty of both the Pareto frontier, as well as the probabilities that an athlete was on the Pareto frontier, the following steps were used:
Draw a data set consisting of 10-second and 20-minute rolling averages by sampling from the posterior predictive distribution arising from the marginal model of the fitted Bayesian bivariate mixed model.
Repeat steps 1 and 2 4,000 times to generate 4,000 first, second and third Pareto frontiers.
Calculate the median and the central 50% interval of the posterior predictive distributions for the first, second and third Pareto frontiers for the 20-minute rolling average across the domain of possible rolling 10-second averages (i.e., 270, 271,…., 375 m·min-1).
Show the code:
frontiers <- combined_df_pareto %>%ungroup() %>%group_by(Sim) %>%filter(.level <=3) %>%ungroup() %>%mutate(R10s =round(R10s /3, 0) *3) %>%filter(R10s >=270& R10s <375) %>%group_by(R10s, .level) %>%point_interval(R20m, .width =c(.50)) %>%mutate(Frontier =case_when(.level ==1~"First", .level ==2~"Second", .level ==3~"Third")) # Calculate the median and middle 50% estimate for rolling 20-minute for each interval of 10-second average smoothed to bins of 3.
Estimate the probability of each athlete being on the first, second, or third Pareto frontier by dividing the frequency that an athlete appeared on the corresponding Pareto frontier by the total number of posterior draws (i.e., 4,000 draws).
The mixed model allowed for the visualisation of the estimated athlete effects for low and high intensity periods and utilised Pareto frontiers to identify the “extreme” athletes. As some athletes played in multiple positions across the three years, position was included as a random effect alongside the match ID to account for match-to-match variability in the team. A normal prior with a mean of 0 and SD of 10 was set for the regression coefficients related to the rolling 10-second average and a normal prior with a mean of 0 and SD of 100 was set for the regression coefficients related to the rolling 20-minute average. Given the multivariate mixed model was implemented in a Bayesian framework, samples can be drawn from the posterior distribution in which the Pareto frontier can be generated for each sample. By summarising the results of all these posterior samples, the probability of each athlete being on the Pareto front can be estimated, thus quantifying the uncertainty.
All analysis was performed in R v4.1.1 (R Core Team, 2019). The brms package (an interface to Stan programming language) (Bürkner, 2017), was used to calculate the posterior distributions for each athlete, the rPref package (Roocks, 2016) was used to generate the Pareto frontiers, and the tidyverse suite of packages were used for all data manipulation, calculation of rolling-average blocks, and all visualisations.
6.4 Results
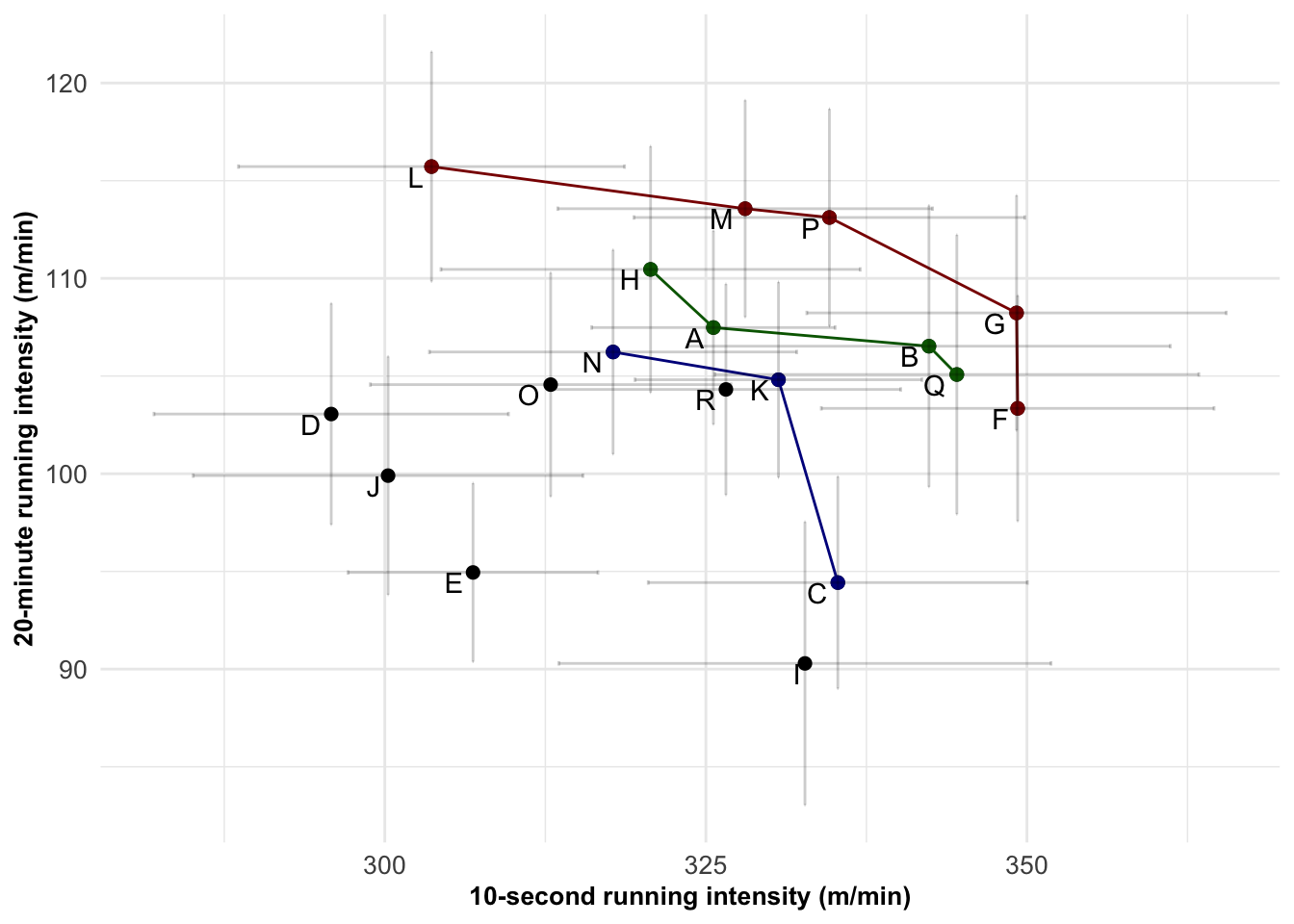
Using the conditional means generated from the multivariate mixed model, the average 10-second rolling mean speed was 325.1 m·min-1 (95% Credible Interval: 304.6 - 346.1 m·min-1) while the average 20-minute rolling mean speed was 104.7 (97.0 - 112.8) m·min-1. There was negligible correlation between the 10-second rolling mean speed and 20-minute rolling mean speed (r = 0.03). However, there was a moderate negative correlation between the rolling 10-second and 20-minute rolling averages for the athletes that were on the first three Pareto frontiers (r = -0.49), which are highlighted in Figure 6.1. Four athletes were identified on the first Pareto frontier, four athletes on the second frontier, and five athletes on the third frontier. The three frontiers are visualised in Figure 6.1. Athletes G & L are on the Pareto frontier due to being the highest in the univariate analysis of 10-second rolling mean speed and 20-minute rolling mean speed respectively, athlete M is on the Pareto frontier as 2nd-highest for 20-minute rolling mean speed and 9th-highest for 10-second rolling mean speed, while athlete P is also on the Pareto frontier despite being 3rd-highest for 20-minute rolling mean speed and 6th-highest for 10-second rolling mean speed.
Figure 6.1: Conditional means of a 10-second rolling average and a 20-minute rolling average mean speed. N.B. Error bars represent the 95% credible interval.
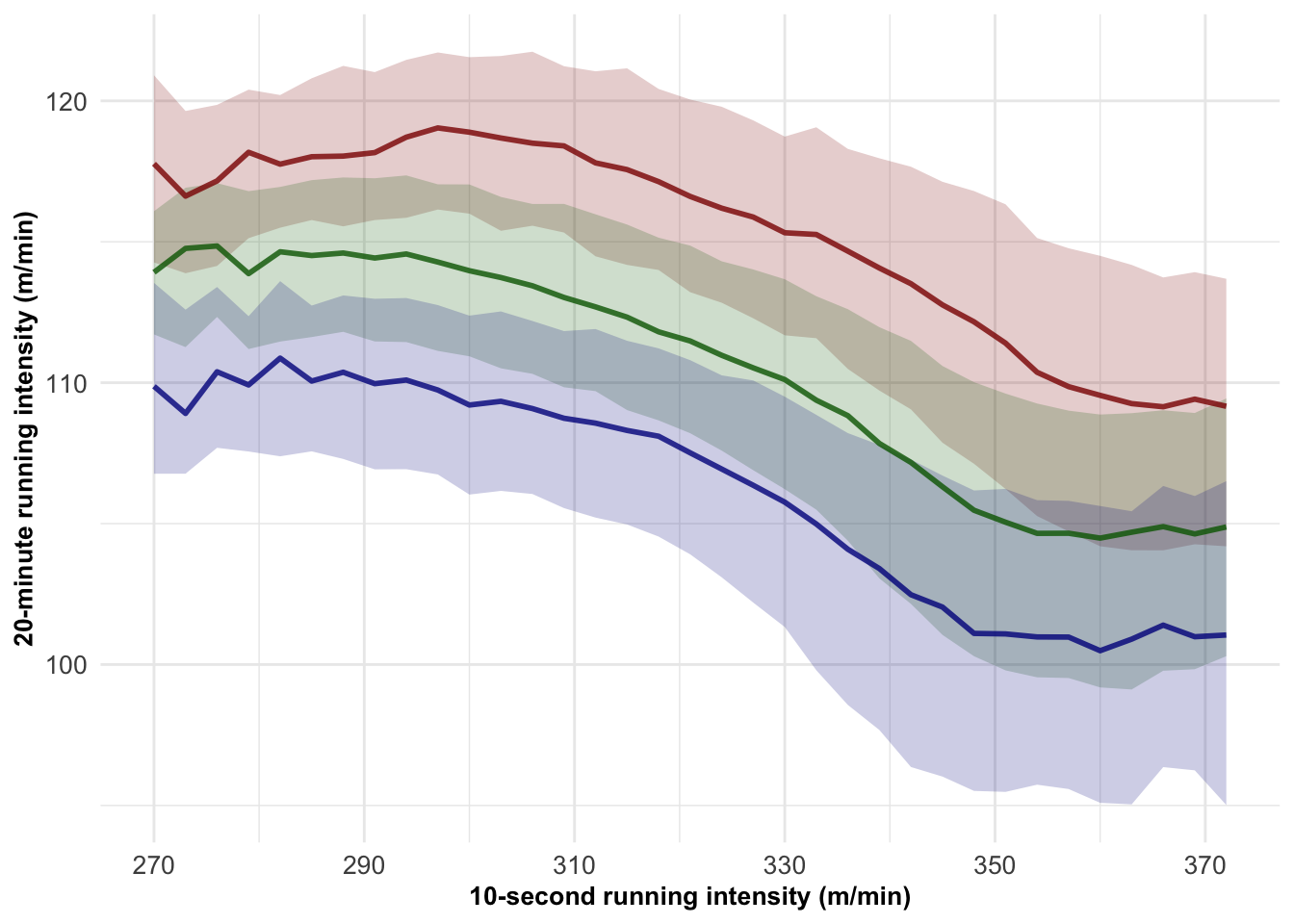
From the multivariate mixed model, 4,000 simulated data sets were drawn from the posterior predictive distribution of the 10-second rolling average and 20-minute rolling average mean speed. Figure 6.2 illustrates the uncertainty around the first, second, and third Pareto frontiers based on these 4000 posterior predictive data sets.
Show the code:
ggplot(data = frontiers, aes(x = R10s, y = R20m, ymin = .lower, ymax = .upper, fill = Frontier, color = Frontier)) +geom_ribbon(alpha =0.2, color =NA) +geom_line(linewidth =1, alpha =0.8) +scale_color_manual(values =c("darkred", "darkgreen", "darkblue")) +scale_fill_manual(values =c("darkred", "darkgreen", "darkblue")) +scale_x_continuous(breaks =seq(270, 370, by =20)) +theme_minimal() +labs(x ="10-second running intensity (m/min)",y ="20-minute running intensity (m/min)") +theme(legend.position ="none",axis.title =element_text(size =10, color ="black", face ="bold"),axis.text =element_text(size =10) )
Figure 6.2: Estimation of the first three Pareto frontiers of the relationship between a 10-second rolling average and a 20-minute rolling average mean speed. The line represents the median Pareto frontier, while the ribbon represents the middle 50% of draws from the posterior predictive distribution of both the 10-second rolling average and 20-minute rolling average mean speed.
From the 4,000 simulated data sets of the 10-second rolling average and 20-minute rolling averages, the probabilities that an individual sits on each frontier were estimated. For this squad, the analysis is shown in Table 6.1.
Show the code:
combined_df_pareto %>%ungroup() %>%group_by(Athlete, .level) %>%summarise(n =n() /nrow(.) *18) %>%pivot_wider(names_from = .level, values_from = n) %>%mutate(Plus4 =rowSums(across(`4`:colnames(.)[ncol(.)]), na.rm =TRUE),across(`1`:Plus4, round, 5),across(`1`:Plus4, ~ . *100)) %>%select(Athlete:`3`, Plus4) ## Calculate the proportions of each athlete on each frontier
Table 6.1: Example squad analysis of the probabilities for each athlete being located on the Pareto frontier between 10-second and 20-minute rolling averages.
Athlete
1st Frontier (%)
2nd Frontier (%)
3rd Frontier (%)
4th or worse Frontier (%)
A
5.4
24.0
34.1
36.5
B
30.7
28.5
19.8
20.9
C
4.6
15.3
26.0
54.2
D
0.2
2.1
8.9
88.9
E
0.0
0.1
1.4
98.5
F
30.4
32.5
22.4
14.7
G
46.2
31.5
13.9
8.5
H
20.7
27.8
23.2
28.3
I
6.2
13.1
19.0
61.7
J
0.2
2.0
6.2
91.6
K
5.4
21.3
32.7
40.6
L
38.0
31.9
17.5
12.6
M
44.1
29.45
15.5
10.9
N
5.7
15.2
23.1
56.0
O
2.5
11.3
18.8
67.5
P
46.5
31.1
14.6
7.8
Q
33.5
27.3
18.8
20.4
R
5.3
16.6
26.7
51.4
6.5 Discussion
The present study aimed to quantify the locomotion patterns of elite-level female footballers during matches and use Pareto frontiers to identify athletes with the highest running intensities in both short (10 seconds) and long (20 minutes) periods in a match. When analysing the data univariately, there was no athlete that, on average, recorded both the highest 10-second and 20-minute rolling average windows, meaning a multivariate approach was justified to explore the trade-off relationship. While there was no correlation between the 10-second and 20-minute rolling average windows across the whole cohort; when considering the multivariate analysis, there was a negative relationship between those were on the first three Pareto frontiers. The present study also quantified the uncertainty around the Pareto frontier through a Bayesian mixed model to provide coaches additional information for athletes with only limited data to start individualising prescription earlier after taking the uncertainty into consideration.
Given that no athlete recorded both the highest 10-second and 20-minute rolling average windows, a Pareto frontier consisting of four athletes (Athletes L, M, P, and G) was established. That is, no other athlete was higher in both the 10-second and 20-minute rolling averages than these four athletes. Although it had been hypothesised that there would be a negative relationship between the 10-second and 20-minute rolling averages based on previous research (Crielaard & Pirnay, 1981), no such relationship was identified. Previous research had identified a negative relationship between the initial sprint time and the resulting RSA decrement score (i.e., an athlete with a faster sprint speed experiences a more severe decrement) (Bishop et al., 2001). Similarly, there is also a negative relationship between the RSA decrement score and maximal oxygen uptake (i.e., VO2max) (i.e., an athlete with a higher VO2max experiences a less severe decrement) (Rampinini et al., 2009). Consequently, Rampinini et al. (2009) hypothesized that a positive relationship between initial sprint time and VO2MAX would exist (i.e., an athlete with a faster initial sprint time would have a lower VO2MAX); curiously however, no significant relationship was evident (Rampinini et al., 2009). These findings are akin to the present study where no relationship was identified between the 10-second and 20-minute rolling averages. Therefore, it is thought that a Simpson’s paradox was present in the data, in which either the quality of an athlete or the opportunity to run is limited by strategic or tactical decisions (Abbott et al., 2018; Hennessy & Jeffreys, 2018) which led to no relationship being present. To test this, when looking at the relationship between only the first three Pareto frontiers, there was indeed a negative relationship between the two running intensities. That is, the six athletes that were not present on the first three Pareto frontiers (i.e., athletes located in the lower left quadrant of Figure 6.1) obfuscate the correlation between the two running intensities due to either tactical or position constraints (i.e., limited opportunities to perform maximal running efforts) or limited physical qualities (i.e., lower training status).
Unlike previous studies utilizing Pareto frontiers which have been purely descriptive (Gunantara, 2018; Mastroddi & Gemma, 2013; Newans, Bellinger, & Minahan, 2022), the present study extended Pareto frontiers into inferential statistics. While the predominant inferential statistics in sports science is frequentist (Santos-Fernandez et al., 2019), the use of a Bayesian mixed model was required to estimate the probabilities that an individual sits on each frontier. The frequentist framework returns a point estimate of the model parameter, typically the maximum likelihood estimate. In contrast, the Bayesian framework produces a posterior distribution for the model parameter, which can then be propagated into uncertainty analysis of the Pareto frontiers by generating plausible data sets from the posterior predictive distribution and constructing a Pareto front for each of these predictive data sets. For instance, the athlete labeled “P” on Figure 6.1, while sitting on the Pareto frontier when plotting the sample data, still only has a 47% probability that they are on the true Pareto frontier. Similarly, there is 31% probability that they are on the 2nd Pareto frontier, a 15% probability that they are on the 3rd Pareto frontier, with only a 8% probability that they are on the 4th or higher Pareto frontier.
This study used a mixed model within a Bayesian framework to quantify the uncertainty around the Pareto frontier. Consequently, the probabilities that each athlete was on the Pareto frontier could be estimated, having accounted for the uncertainty of each athlete. The approach of generating a credible interval for the Pareto frontier to determine the probability that an athlete sits on different frontiers was novel, with a similar approach only seen in portfolio construction in finance (Bauder et al., 2021); however, these did not require a mixed model to accounted for the imbalanced data like that seen in the present study. Given the variability in the data set and with some athletes only playing a limited number of matches, the mixed model generated large credible intervals around each of the conditional means. Consequently, the interpretation of the conditional mean Pareto frontier is limited as there is uncertainty whether the athlete truly lies on the population Pareto frontier. Using a Bayesian framework allows the uncertainty to be estimated for whether an athlete sits on the Pareto frontier, as well as calculating the uncertainty of where the Pareto frontier lies across the whole Cartesian plane.
While the present study illustrated how to analyse the balance between the two running intensities, the application of the statistical methods used in this study, namely, a Bayesian mixed model, to estimate the uncertainty around the Pareto frontier is wide-reaching and can be used in any sporting or other context where there are conflicting attributes that are equally desirable. By understanding which frontier an athlete is located in, coaches are provided additional information to devise training sessions that are targeted at improving both speed (i.e., 10 s) and endurance (i.e., 20 min) running performance that is relevant to match-specific running intensities. Similarly, when new squad members are introduced, identification of the various frontiers allows new squad members to be categorised into training groups with athletes displaying a similar locomotion profile within a given position.
Abbott, W., Brickley, G., & Smeeton, N. (2018). Positional differences in GPS outputs and perceived exertion during soccer training games and competition. The Journal of Strength & Conditioning Research, 32(11), 3222–3231. https://doi.org/10.1519/JSC.0000000000002387
Bauder, D., Bodnar, T., Parolya, N., & Schmid, W. (2021). Bayesian mean-variance analysis: Optimal portfolio selection under parameter uncertainty. Quantitative Finance, 21(2), 221–242. https://doi.org/10.1080/14697688.2020.1748214
Bishop, D., Spencer, M., Duffield, R., & Lawrence, S. (2001). The validity of a repeated sprint ability test. Journal of Science and Medicine in Sport, 4(1), 19–29. https://doi.org/10.1016/S1440-2440(01)80004-9
Brown, D., Dwyer, D., Robertson, S., & Gastin, P. (2016). Metabolic power method: Underestimation of energy expenditure in field-sport movements using a global positioning system tracking system. International Journal of Sports Physiology and Performance, 11(8), 1067–1073. https://doi.org/10.1123/ijspp.2016-0021
Buchheit, M., Manouvrier, C., Cassirame, J., & Morin, J.-B. (2015). Monitoring locomotor load in soccer: Is metabolic power, powerful? International Journal of Sports Medicine, 36(14), 1149–1155. https://doi.org/10.1055/s-0035-1555927
Bürkner, P.-C. (2017). Brms: An r package for bayesian multilevel models using stan. Journal of Statistical Software, 80(1), 1–28. https://doi.org/10.18637/jss.v080.i01
Coutts, A., Quinn, J., Hocking, J., Castagna, C., & Rampinini, E. (2010). Match running performance in elite Australian Rules Football. Journal of Science and Medicine in Sport, 13(5), 543–548. https://doi.org/10.1016/j.jsams.2009.09.004
Crielaard, J.-M., & Pirnay, F. (1981). Anaerobic and aerobic power of top athletes. European Journal of Applied Physiology and Occupational Physiology, 47(3), 295–300. https://doi.org/10.1007/BF00422475
Cummins, C., Orr, R., O’Connor, H., & West, C. (2013). Global Positioning Systems (GPS) and microtechnology sensors in team sports: A systematic review. Sports Medicine, 43(10), 1025–1042. https://doi.org/10.1007/s40279-013-0069-2
Cunningham, D., Shearer, D., Carter, N., Drawer, S., Pollard, B., Bennett, M., Eager, R., Cook, C., Farrell, J., Russell, M., & Kilduff, L. (2018). Assessing worst case scenarios in movement demands derived from global positioning systems during international rugby union matches: Rolling averages versus fixed length epochs. PLoS One, 13(4), e0195197. https://doi.org/10.1371/journal.pone.0195197
Dalton-Barron, N., Whitehead, S., Roe, G., Cummins, C., Beggs, C., & Jones, B. (2020). Time to embrace the complexity when analysing GPS data? A systematic review of contextual factors on match running in rugby league. Journal of Sports Sciences, 38(10), 1161–1180. https://doi.org/10.1080/02640414.2020.1745446
Delaney, J., Scott, T., Thornton, H., Bennett, K., Gay, D., Duthie, G., & Dascombe, B. (2015). Establishing duration-specific running intensities from match-play analysis in rugby league. International Journal of Sports Physiology and Performance, 10(6), 725–731.
Delaney, J., Wileman, T., Perry, N., Thornton, H., Moresi, M., & Duthie, G. (2019). The validity of a global navigation satellite system for quantifying small-area team-sport movements. The Journal of Strength and Conditioning Research, 33(6), 1463. https://doi.org/10.1519/JSC.0000000000003157
Deutsch, M., Kearney, G., & Rehrer, N. (2007). Time-motion analysis of professional rugby union players during match-play. Journal of Sports Sciences, 25(4), 461–472. https://doi.org/10.1080/02640410600631298
Doncaster, G., Page, R., White, P., Svenson, R., & Twist, C. (2020). Analysis of physical demands during youth soccer match-play: Considerations of sampling method and epoch length. Research Quarterly for Exercise and Sport, 91(2), 326–334. https://doi.org/10.1080/02701367.2019.1669766
Fereday, K., Hills, S., Russell, M., Smith, J., Cunningham, D., Shearer, D., McNarry, M., & Kilduff, L. (2020). A comparison of rolling averages versus discrete time epochs for assessing the worst-case scenario locomotor demands of professional soccer match-play. Journal of Science and Medicine in Sport, 23(8), 764–769. https://doi.org/10.1016/j.jsams.2020.01.002
Hennessy, L., & Jeffreys, I. (2018). The current use of GPS, its potential, and limitations in soccer. Strength & Conditioning Journal, 40(3), 83–94. https://doi.org/10.1519/SSC.0000000000000386
Mastroddi, F., & Gemma, S. (2013). Analysis of Pareto frontiers for multidisciplinary design optimization of aircraft. Aerospace Science and Technology, 28(1), 40–55. https://doi.org/10.1016/j.ast.2012.10.003
McKay, A., Stellingwerff, T., Smith, E., Martin, D., Mujika, I., Goosey-Tolfrey, V., Sheppard, J., & Burke, L. (2021). Defining training and performance caliber: A participant classification framework. International Journal of Sports Physiology and Performance, 17(2), 317–331. https://doi.org/10.1123/ijspp.2021-0451
Mohr, M., Krustrup, P., & Bangsbo, J. (2003). Match performance of high-standard soccer players with special reference to development of fatigue. Journal of Sports Sciences, 21(7), 519–528. https://doi.org/10.1080/0264041031000071182
Newans, T., Bellinger, P., Buxton, S., Quinn, K., & Minahan, C. (2021). Movement patterns and match statistics in the national rugby league women’s (NRLW) premiership. Frontiers in Sports and Active Living, 3. https://doi.org/10.3389/fspor.2021.618913
Newans, T., Bellinger, P., Drovandi, C., Buxton, S., & Minahan, C. (2022). The utility of mixed models in sport science: A call for further adoption in longitudinal data sets. International Journal of Sports Physiology and Performance, 17(8), 1289–1295. https://doi.org/10.1123/ijspp.2021-0496
Newans, T., Bellinger, P., & Minahan, C. (2022). The balancing act: Identifying multivariate sports performance using Pareto frontiers. Frontiers in Sports and Active Living, 4. https://doi.org/10.3389/fspor.2022.918946
Novak, A., Impellizzeri, F., Trivedi, A., Coutts, A., & McCall, A. (2021). Analysis of the worst-case scenarios in an elite football team: Towards a better understanding and application. Journal of Sports Sciences, 39(16), 1850–1859. https://doi.org/10.1080/02640414.2021.1902138
Quinn, K., Newans, T., Buxton, S., Thomson, T., Tyler, R., & Minahan, C. (2020). Movement patterns of players in the Australian Women’s Rugby League team during international competition. Journal of Science and Medicine in Sport, 23(3), 315–319. https://doi.org/10.1016/j.jsams.2019.10.009
R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
Rampinini, E., Sassi, A., Morelli, A., Mazzoni, S., Fanchini, M., & Coutts, A. (2009). Repeated-sprint ability in professional and amateur soccer players. Applied Physiology, Nutrition, and Metabolism, 34(6), 1048–1054. https://doi.org/10.1139/H09-111
Roocks, P. (2016). Computing Pareto frontiers and database preferences with the rPref package. The R Journal, 8(2), 393–404. https://doi.org/10.32614/RJ-2016-054
Santos-Fernandez, E., Wu, P., & Mengersen, K. (2019). Bayesian statistics meets sports: A comprehensive review. Journal of Quantitative Analysis in Sports, 15(4), 289–312. https://doi.org/10.1186/s12888-018-1761-4
Stølen, T., Chamari, K., Castagna, C., & Wisløff, U. (2005). Physiology of soccer: An update. Sports Medicine (Auckland, N.Z.), 35(6), 501–536. https://doi.org/10.2165/00007256-200535060-00004
Varley, M., Elias, G., & Aughey, R. (2012). Current match-analysis techniques’ underestimation of intense periods of high-velocity running. International Journal of Sports Physiology and Performance, 7(2), 183–185. https://doi.org/10.1123/ijspp.7.2.183
Weaving, D., Young, D., Riboli, A., Jones, B., & Coratella, G. (2022). The maximal intensity period: Rationalising its use in team sports practice. Sports Medicine-Open, 8(1), 1–9. https:doi.org/10.1186/s40798-022-00519-7